Why Long-Form Text Generation Is Harder Than It Looks (And How We Solved It)
Large language models have transformed how we interact with text. They can summarize documents, answer questions, write code, and generate creative content with remarkable fluency. However, when it comes to long-form generation, such as producing a comprehensive 5,000-word research report with accurate citations and coherent argumentation across sections, things start to fall apart.
At Elutri Labs, we build AI-powered tools for investment research, a domain where analysts need thorough, well-sourced documents that synthesize information across hundreds of sources. This isn’t a use case where “pretty good” is acceptable. A hallucinated statistic or a citation that doesn’t actually say what you claim it says isn’t just annoying; it’s a professional liability.
This post explains why long-form generation is genuinely difficult, and how we architected around these challenges in our FAR Engine platform.
The Core Challenges
The problems with long-form LLM generation aren’t obvious until you’ve tried to productionize it. Here’s what the research literature and our own experience have taught us.
Output Length Is the Real Bottleneck
There’s a common misconception that context window size is the limiting factor. Models now support 128K to 1M token inputs, which sounds like plenty. But the constraint isn’t input, it’s output.
Research from early 2025 documented that even models capable of processing 100,000+ input tokens typically struggle to produce outputs longer than 2,000 words. Proprietary models often impose hard output limits of 4,096 or 8,192 tokens regardless of input capacity. The underlying issue is that supervised fine-tuning datasets simply lack examples of high-quality long outputs. Models haven’t seen enough good long-form writing during training to learn how to produce it.
The “Lost in the Middle” Problem
This is perhaps the most underappreciated challenge. LLM performance is highest when relevant information appears at the beginning or end of the input context, and significantly degrades when models must access information in the middle, even for models explicitly designed for long contexts.
The effect resembles the psychological “serial-position effect” in human memory: we remember the first and last items in a list better than those in the middle. But unlike human memory, this isn’t a fundamental limitation, it’s an artifact of how attention mechanisms are trained. For practical purposes, though, it means that even when you include all relevant sources in the context window, the model may ignore them based purely on their position.
Inter-Paragraph Coherence
Short-form generation is forgiving. If you’re producing a three-paragraph response, the model can hold the entire structure in its effective attention. Long-form content is different. Generating a coherent 20-section document requires maintaining consistency when the model has effectively “forgotten” what it wrote in earlier sections.
Models struggle particularly when improvising arguments on the fly rather than following a structured plan. Cognitive writing theory suggests effective writing emerges from planning, translating, and reviewing, but LLMs typically skip the planning phase entirely, attempting to generate polished prose in a single pass.
Citation Accuracy
This one is sobering. Research on generative search engines found that responses frequently contain unsupported statements and inaccurate citations. On average, only 51.5% of generated sentences are fully supported by their citations, and only 74.5% of citations actually support their associated sentence.
Even more concerning: citation recall and precision are inversely correlated with fluency and perceived utility. The responses that appear most helpful often have the lowest citation accuracy. This makes intuitive sense, confident, flowing prose is easier to generate when you’re not constrained by what your sources actually say.
Information Density Degradation
When LLMs generate long text, they tend to pad with repetition and filler. LLM-generated text typically shows much lower information entropy than human-authored text of equivalent length. The result is documents that feel bloated and repetitive, frustrating for readers who want dense, substantive analysis.
Continuation Drift
A common workaround for output length limits is to ask the model to “continue” from where it left off. This introduces its own problems. Further continuation requests introduce continuity errors and hallucinations because earlier context falls out of effective attention or gets summarized poorly. Each continuation is essentially a new generation task that has to reconstruct context from an increasingly unreliable summary.
RAG Doesn’t Fully Solve Hallucination
Retrieval-Augmented Generation helps ground outputs in source documents, but it introduces new failure modes. Limitations within RAG components can cause hallucinations, including data source quality issues, query formulation problems, retriever failures, and context conflicts when retrieved documents contradict each other. RAG is necessary but not sufficient.
Our Approach: Structure-First Generation
The fundamental insight behind our approach is that long-form generation fails when treated as a single generation task. The solution is to decompose it into a structure-building phase followed by contextualized section generation.
Stage 1: Building the Knowledge Scaffold
Before any writing happens, our system constructs a hierarchical knowledge base through a process we call “warmstart.” This involves multi-agent discussion that explores a topic, retrieves relevant information, and organizes findings into a mind-map structure. We’ll cover the warmstart mechanics in a future post, for now, the key point is that the knowledge structure is built through research, not imposed top-down.
The resulting knowledge base has several important characteristics. It’s organized as a hierarchical parent-child tree of knowledge nodes. Each node links to retrieved information via semantic similarity. Nodes expand dynamically based on information density thresholds, sparse areas get more exploration, while well-covered areas don’t need additional retrieval.
Critically, every piece of information maintains its provenance: what question triggered its retrieval, what search query produced it, and full source metadata including URL, title, and timestamp. Each information snippet has a UUID that follows it through the entire pipeline. Citations aren’t retrofitted after the fact, they’re native to the knowledge structure from the moment information is retrieved.
Stage 2: Structure Becomes Document Outline
Each node in the knowledge hierarchy becomes a section or subsection in the final document. This is a direct mapping, the structure that emerged from research becomes the structure of the report.
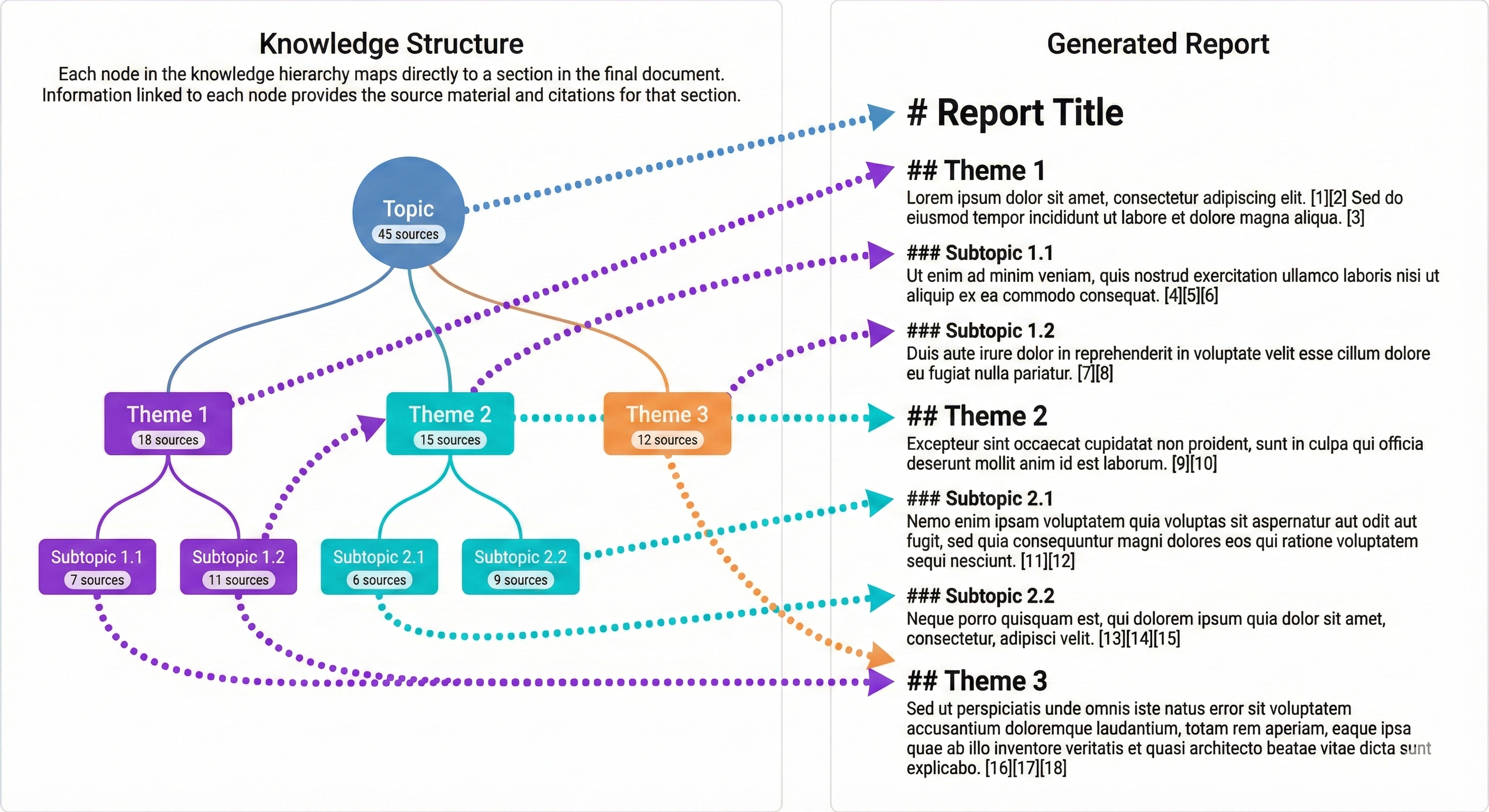
This approach has a subtle but important benefit: the document structure reflects what the research actually found, rather than forcing findings into a predetermined template. If a particular theme warranted deep exploration (producing many child nodes), it gets corresponding depth in the final document.
Stage 3: Hierarchical Generation with Context Inheritance
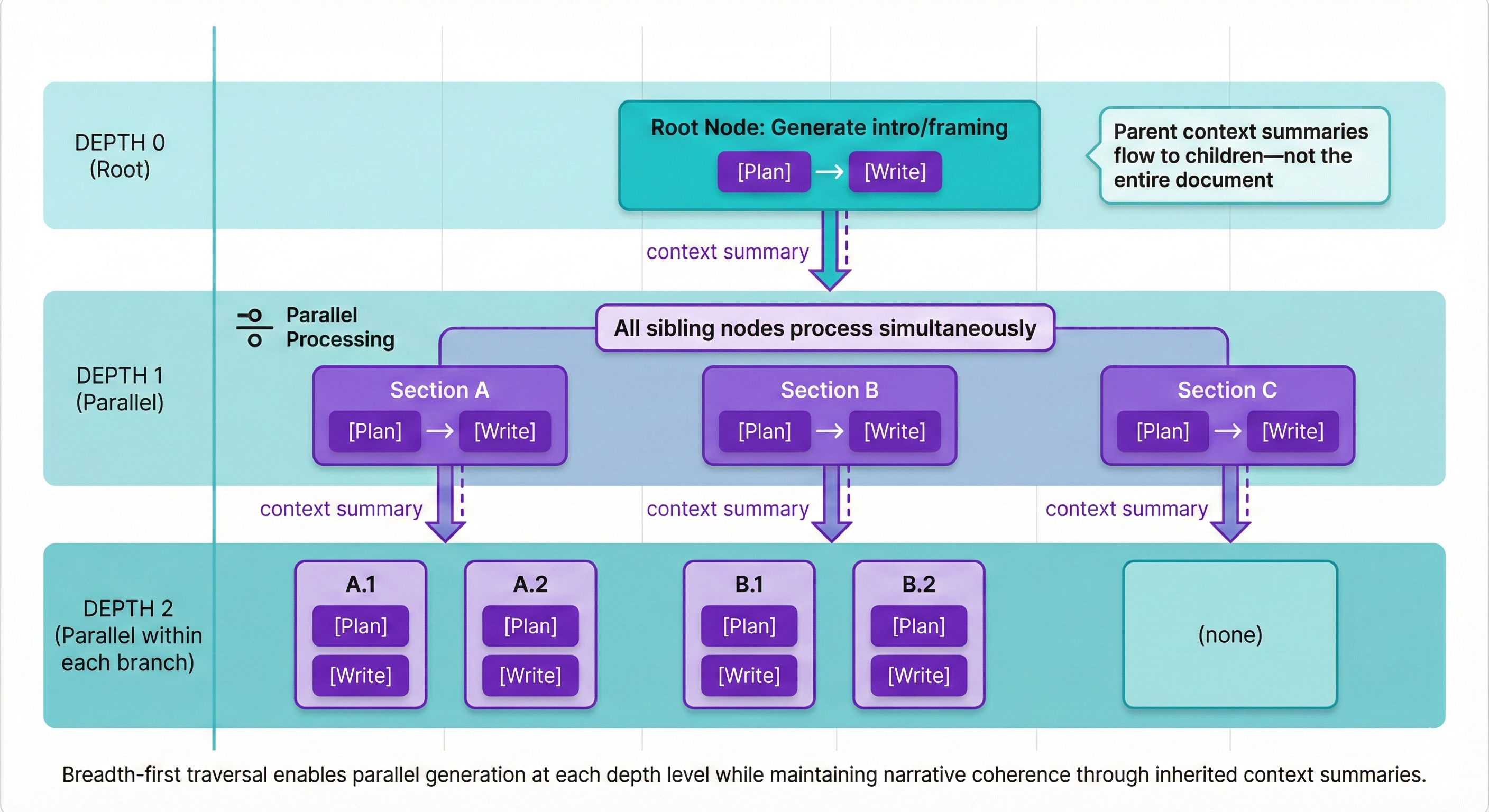
With the structure established, the system traverses the knowledge hierarchy breadth-first, generating each section through a two-step process: first planning what will be written, then writing against that plan.
The key mechanisms here are worth understanding:
Context inheritance solves the coherence problem. Each section receives context summaries from its parent nodes, cumulative summaries of themes, key points, and narrative tone. This maintains coherence without stuffing the entire document into the context window. A subsection on “Geographic Revenue Concentration” knows it’s part of a broader “Risk Factors” section, which itself fits into an overall analysis with a particular analytical stance.
Lost-in-the-middle mitigation is built into the architecture. Because each section is generated with only its relevant context (parent summaries plus linked information), the relevant material is positioned where the model actually attends to it, at the beginning of that section’s context window.
Parallel processing at each depth level dramatically reduces total generation time. Sibling sections generate simultaneously because they don’t depend on each other’s output, only on their shared parent’s context summary.
Selective Refinement
Not every section needs the same level of attention. We use embedding-based quality scoring to identify sections below threshold, then apply an iterative review-revise cycle only to those sections.
The refinement loop is simple: an LLM reviews the section and provides quality feedback, then a separate pass improves the section based on that feedback. This repeats up to a configured maximum (typically 2-3 iterations).
This approach prevents two failure modes. First, it avoids wasting compute on sections that are already good. Second, and less obviously, it prevents over-polishing. Excessive refinement passes can introduce new errors or flatten a distinctive analytical voice into generic prose. The quality gate ensures we iterate only where it’s needed.
Citation Integrity by Design
Because every information snippet carries its source metadata through the entire pipeline, citation validation becomes verification rather than generation.
The flow works like this: information is retrieved with full source metadata and a UUID. It’s stored in the knowledge base with that metadata intact. During section generation, the writer uses inline citation markers [1][2] that reference specific UUIDs. Final document assembly maps citation numbers to verified source UUIDs. The reference list includes only sources that were actually retrieved and used, there’s no opportunity for hallucinated URLs because citations can only point to information that exists in the knowledge base.
This is a fundamentally different approach from asking a model to “add citations” after writing. Post-hoc citation is essentially asking the model to generate plausible-looking references, which is exactly the kind of task LLMs are bad at.
The Architecture in Summary
The approach works because it respects what LLMs are good at (fluent prose generation within a focused context) while architecting around what they’re bad at (maintaining coherence across long documents, accurate citation, and self-correction).
By decomposing long-form generation into knowledge building, structure mapping, and hierarchical section generation, each individual generation task stays within the regime where LLMs perform well. Context inheritance maintains coherence without overwhelming context windows. Citation integrity is enforced by design rather than hoped for as an emergent property.
This is the foundation of how we generate investment research reports in the FAR Engine. Future posts will dive deeper into the warmstart process for knowledge building, the multi-agent discussion architecture, and how we handle the particular challenges of financial document analysis.
References
The claims in this post are grounded in recent research on long-form generation and retrieval-augmented systems. For those interested in the underlying literature:
On output length limitations:
- Zhang et al., “Shifting Long-Context LLMs Research from Input to Output” (arXiv, 2025)
- Bai et al., “LongWriter: Unleashing 10,000+ Word Generation from Long Context LLMs” (2024)
On the “lost in the middle” problem:
- Liu et al., “Lost in the Middle: How Language Models Use Long Contexts” (TACL, 2024) , the paper that named and quantified this phenomenon
On citation accuracy:
- Gao et al., “ALCE: Enabling Large Language Models to Generate Text with Citations” (Princeton, 2023)
- Min et al., “FActScore: Fine-grained Atomic Evaluation of Factual Precision” (2023)
On RAG failure modes:
- Li et al., “Hallucination Mitigation for Retrieval-Augmented Large Language Models: A Review” (arXiv, 2025)
On plan-based and hierarchical generation:
- Liu et al., “RAPID: Efficient Retrieval-Augmented Long Text Generation with Planning and Information Discovery” (ACL, 2025)
- Shao et al., “STORM: Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models” (Stanford, 2024)
- Chen et al., “LongRefiner: Query-Aware Long-Context Refinement for Retrieval-Augmented Generation” (2024)
On grounded generation and attribution:
- Menick et al., “Teaching Language Models to Support Answers with Verified Quotes” (DeepMind GopherCite, 2022)
- Gao et al., “RARR: Researching and Revising What Language Models Say, Using Language Models” (2023)
- Asai et al., “Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection” (2024)